What is Robots.txt File and How to Manage Crawlers?
Robots.txt file acts like an entry gate to a website. It contains useful instructions for web crawlers on what they are allowed and disallowed.
How robots.txt File Works?
robots.txt file contains a Protocol or list of instructions for a web crawler for do’s and Don’t’s. Although robots can ignore these instructions, but they are obliged to do so.
Why You Should Use robots.txt?
You can use robots.txt file to for diversified purposes.
- Convey your sitemap location to a Web Crawler / Search Engine Bot
- Robots.txt file is used to specify those pages/posts and content which you don’t want a crawler to crawl. This is achieved by using Disallowed directive.
- You can use robots.txt to manage your crawl budget.
- You can use robots.txt to inform crawlers to delay the crawling process using
Crawl-Delaydirective.
What are the Contents of a robots.txt file?
robots.txt content consists of directives which contains specific instructions.
1. User-agent
Which User Agents are allowed?. Here are some of the common User Agents?
- Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0
- Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0
2. Disallow
Disallow is used to control which Pages or Directories are not allowed to be crawled?
User-agent: * Disallow: /wp-admin/ # Not allowed to crawl
3. Allow
Allow tells search engine bots that which Pages or Directories are allowed to be crawled?
User-agent: *
Allow: /wp-admin/admin-ajax.php # Allowed to Craw
4. Crawl-Delay Directive
Craw-Delay directive is used to specify that Crawlers must wait for a specific amount of time (seconds) before crawling. This directive is used to avoid overloading of web servers.
User-agent: * # all user agents/crawlers are allowed Crawl-delay: 1 # 1 second delay
5. Sitemap
Contains sitemap.xml file location, which helps Search Engines to find sitemap of the website quickly.
How Robots.txt File Looks Like?
A robots.txt file is a simple text file with directives included in it. See the following examples to check sample content of this file.
Example 1
User-agent: * # Which User agents are allowed to crawl website- * means anyone can crawl Disallow: /wp-admin/ # Not allowed to crawl Allow: /wp-admin/admin-ajax.php # What is extra allowed
Example 2
User-agent: * Disallow: / # Home directory - Home page
Example 3
User-agent: * Disallow: /*.png$ # Blocks crawling of all png files
How to find robots.txt file of a website?
robots.txt files can be found by appending robots.txt to the domain name of a website. In the following figure, we append robots.txt to ahrefs.com to check their robots.txt content.
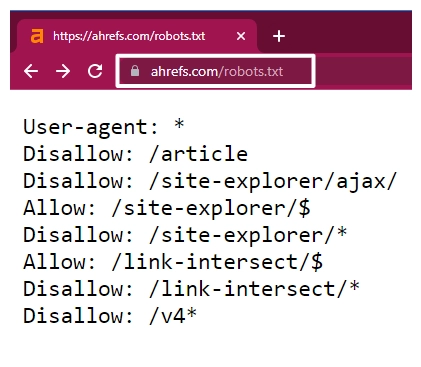
Example contents of a Robots.txt file from ahrefs.com/robots.txt [Image Credits: Faisal Shahzad (SEO Wings)]
Best Practice for Preparing A Robots.txt File
- Use a Single Directive per line.
- Use # (Hash tag) to comment robots.txt file, so that it is easily readable for humans too. See Example 1 and Example 2, where we added those comments.
- A single robots.txt file works for that specific domain. If you have subdomains, then include separate robots.txt for those subdomains. This means you should create
sub.domain.com/robots.txtseparately. - $ Sign at the end of the directive is used to specify the end of the URL. This is very useful for specifying the end of an image file name. See Example 3 for more details.
- Wild cards
[*]are your friend, as log as you use them with precautions. In the above-mentioned example, we use these wild cards to specify user agents. - Save time for yourself and the search engine visiting your website by specifying each user agents for once.
What are some common Robots/Crawlers?
| Bot/Crawler Name | Search Engine Name |
|---|---|
| Applebot | Apple |
| AhrefsBot | Ahrefs |
| Baiduspider | Baidu |
| Bingbot | Microsoft Bing |
| Discordbot | Discord |
| DuckDuckBot | DuckDuckGo |
| Googlebot | Google Search Bot |
| Googlebot-Image | Google Image Bot |
| LinkedInBot | LinkedIn Bot |
| MJ12bot | |
| Pinterestbot | |
| SemrushBot | Semrsh |
| Slurp | |
| TelegramBot | Telegram |
| Twitterbot | Twitter Bot |
| Yandex | Yandex |
| YandexBot | |
| facebot | |
| msnbot | MSN Bot |
| rogerbot | MOZ Bot |
| xenu |
Conclusion
Robots.txt is also an essential part of SEO Strategy. As part of the SEO strategy, one should prepare a list of which content files should be Disallowed and Allowed to be publically available to regular users and search engine bots.
If a website admin does not understand the structure of the robots.txt file, then he/she might block some valuable content that should be available to visitors and search engine bots. Therefore, SEO Masters must understand the content of their robots.txt file and their competitors.
Frequently Asked Questions

Faisal Shahzad
Hi, I am Faisal. I am working in the field of Search Engine Optimization (SEO) and Data Sciences since 2002. I love to hack workflows to make life easy for people around me and myself. This blog contains my random thoughts and notes on Digital Marketing, Affiliate Marketing, Static WordPress Hosting with Netlify and CloudFlare Pages, Python, Data Science and open-source projects.





